Hierarchical clustering (한글 : 계층적 군집 분석) 은 비슷한 군집끼리 묶어 가면서 최종 적으로는 하나의 케이스가 될때까지 군집을 묶는 클러스터링 알고리즘이다
군집간의 거리를 기반으로 클러스터링을 하는 알고리즘이며, K Means와는 다르게 군집의 수를 미리 정해주지 않아도 된다.

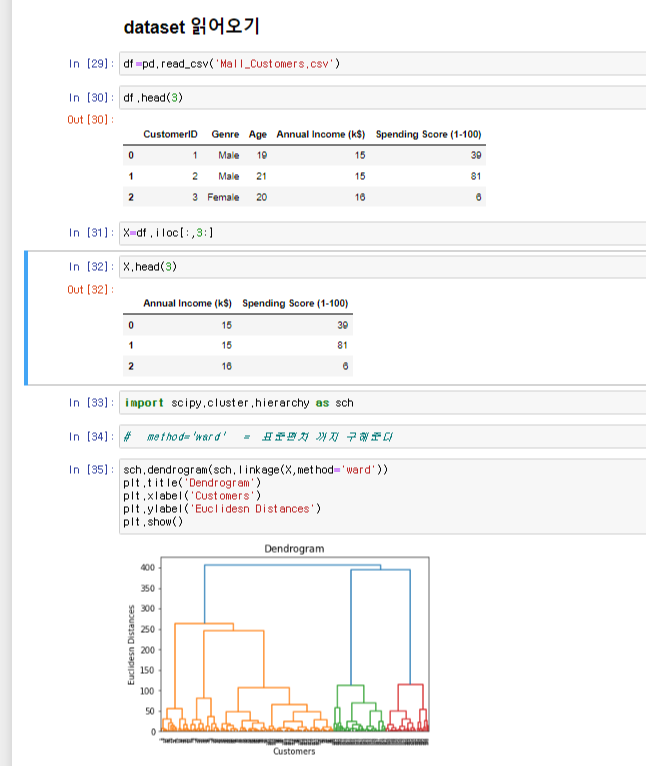
위에 그림은 파일을 불러온 뒤 덴드로그램까지의 코드를 적어놓은 것 이다.
import scipy.cluster.hierarchy as sch
라이브러리를 불러와 덴드로그램을 불러 사용하면 된다.
클러스터의 갯수의 경우 임의자(사람)가 임의로 정하기 때문에
덴드로그램을 보고 임의자가 판단하여 클러스터의 갯수를 정하면 된다 .
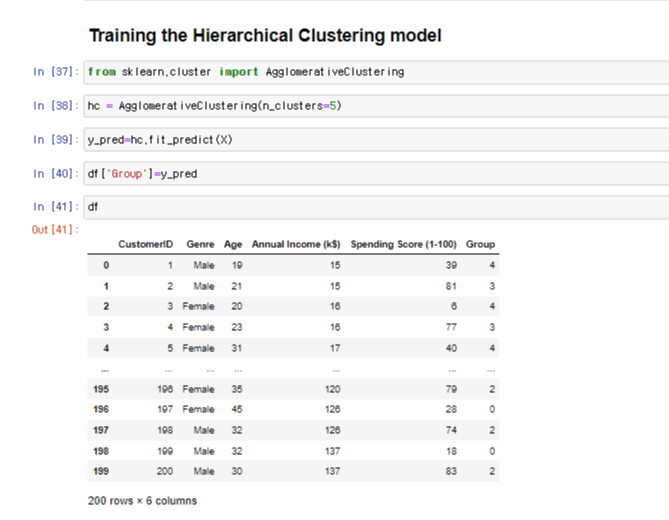
정한 클러스터의 따라 맞는 데이터들이 정해진 클러스터에 들어가게 된다.
정해진 클러스터를 다시 데이터 프레임에 넣어주면 된다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 인공지닝,머신러닝의 기초, 이해 ,기본 설명 (0) | 2021.11.26 |
|---|---|
| 클러스터링 - KMeans(군집화) (0) | 2021.11.26 |
| 머신 러닝 : Decision Tree (0) | 2021.11.25 |
| 머신러닝 : Random Forest , 랜덤 포레스트, 머신러닝 2차원 배열, 1차원,2차원으로 바꾸기 , (0) | 2021.11.25 |
| 12day 5 (0) | 2021.11.24 |