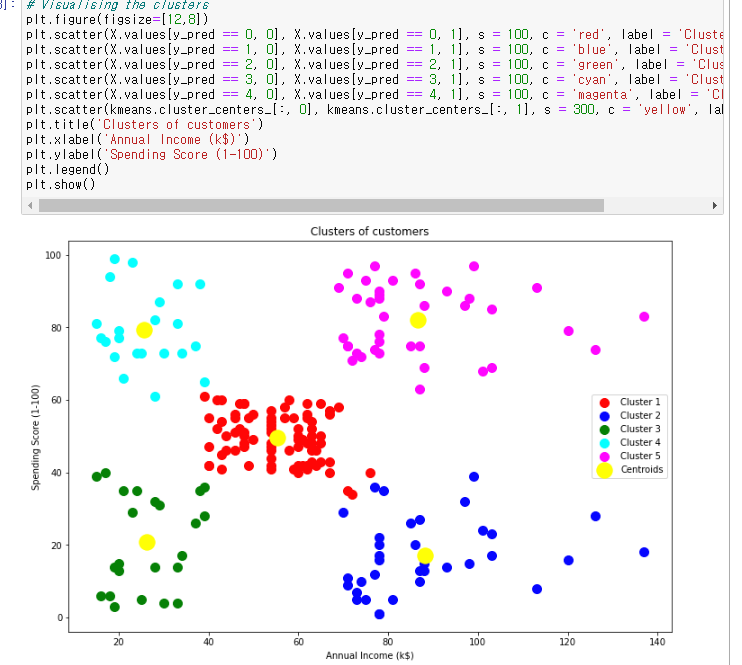
- 데이터를 k개의 클러스터로 묶는 알고리즘입니다.
- Unsupervised이며, 입력 데이터(X)에 대한 레이블링 데이터(Y)가 없이 입력 값 (X 값)의 특성만으로 학습을 진행합니다.
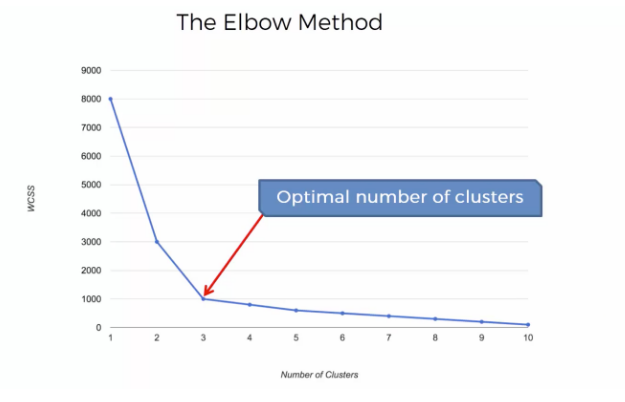
- 사용자가 클러스터의 개수(k)를 정의합니다.
- 임의로 정해진 K라는 값에서 가까인 있는 데이터들을 모아 하나의 그룹을 만들고
- 만들어진 그룹의 중앙값을 기준으로

'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 : hierarchical clustiering 의 Dendrogram ,군집화,덴드로그램 (0) | 2021.11.30 |
|---|---|
| 인공지닝,머신러닝의 기초, 이해 ,기본 설명 (0) | 2021.11.26 |
| 머신러닝: Hierarchical clustering,계층적 클러스터링,덴드로그램,Dendrogram (0) | 2021.11.25 |
| 머신 러닝 : Decision Tree (0) | 2021.11.25 |
| 머신러닝 : Random Forest , 랜덤 포레스트, 머신러닝 2차원 배열, 1차원,2차원으로 바꾸기 , (0) | 2021.11.25 |